Biomedical Data Science

Research Staff
-

Professor
Koichi FUJIWARA -

Affiliate Associate Professor
Takanari IKEYAMA
| fujiwara.koichi@naist.ac.jp | |
| To the site | https://hps.naist.jp/index_eng.html |
Research Areas
- Information infrastructure attack prevention and mitigation techniques
- Reliable communication over mobile networks
- Trusted identity management for modern applications and services
- Workload measurement and characterization
- Construction and management of resilient infrastructures
- Security risk assessment (cloud computing, IoT, etc.)
- IPv6 transition and verification methodologies
- Elastic mechanisms for efficient wireless/wired network management
Key Features
large amount of data appended with such correct answer labels are collected from the Internet and a machine is made to learn them, the machine would be able to automatically find cats in images. This is called "collective intelligence," and it is touted that by allowing the learning of a large amount of data, AI performance would transcend human intelligence in the future, and steal work from many people. But, is this true?
Big data research is already a red ocean. In the AI industry, those who possess a large amount of data, high-speed computers, and numerous skilled engineers, inevitably win. That is, the AI industry is already a device industry, and a game won according to capital strength. In Japan, where we have not heretofore amply invested in human resources or facilities, it is not possible to catch up with GAFA in the big data realm.
The world of small data is a different story. Small data refers to data whose occurrence itself is rare, such as failure data of a particular device, or whose collection is difficult for ethical reasons, such as clinical data on a particular disease. Furthermore, with small data, there are many cases where the interpretation of the data is difficult for anyone but a limited number of experts, and labeling is also high-cost; only skilled medical doctors and specialist technicians can accurately label abnormal brainwaves. Therefore, in a research targeting small data, there is great value in cleaning the data, aligning formats, and constructing datasets that can be analyzed. In small data analysis, it is necessary to proactively incorporate, into the modeling, causal relationships behind the data, knowledge on physics and physiology, various case studies, and know-how and tacit knowledge of experts. Considering that such knowledge is created by a small number of experts, it can be seen that AI performance cannot exceed humans in the field of small data, but, at most, approximate the abilities of a small number of experts.
This kind of small data analysis may seem to be ad hoc and unsystematic from the point of view of theoretical research. However, real-world complex problems cannot be solved only with theory, and requires trial and error. In the process of trial and error, known-how on small data analysis is accumulated, and such know-how would becomes systematized together with knowledge from various other domains. Therefore, research on small data is still a wide open blue ocean.
In our lab, we collect clinical data on patients of epilepsy, sleep disorder, stroke, heat stroke, etc., in collaboration with numerous hospitals and research institutes. From Hokkaido to the north and Okinawa to the south, a network of hospitals and specialists built across Japan, straddling various departments, is our greatest asset. Data that are still lacking are collected by conducting animal and human subject experiments ourselves, and, through their analyses, we are developing diagnostic algorithms and medical devices. Furthermore, through these data analyses, we aim to contribute to basic medicine and physiology, such as elucidating the mechanisms of various diseases.
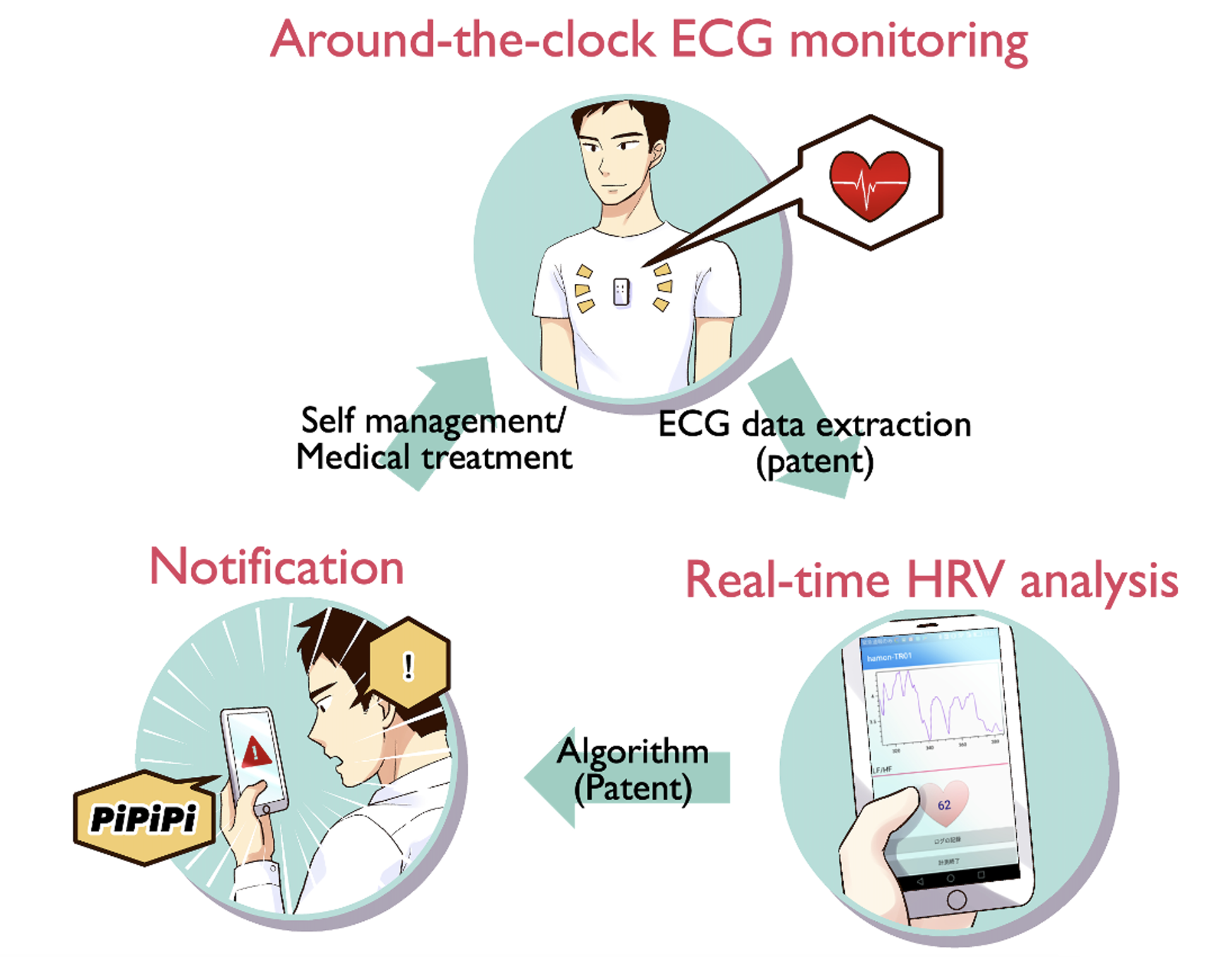
Fig.1 Schematic diagram of epileptic seizure prediction system under development
Fig.2 Original smartphone app for health monitoring