
-
自然言語処理学研究室
澤田 悠冶
Yuya Sawada
抽出対象を自在に制御する固有表現認識技術の開発
自然言語処理 固有表現認識 Few-shot学習 言語モデル -
誰もが平等に情報を得られる社会を目指して
いま話題のChatGPTは、膨大な言語データを学習することで、さまざまな質問への回答が可能となっています。しかし、その回答が正確であるという保証はありません。私たちが日常的に利用している日本語情報検索サービスなども、目的とは異なる情報や、間違った情報が提示されることがあります。さらに、慣れたユーザーであればその結果が間違いであると認識できますが、不慣れなユーザーは誤った情報を信じてしまう危険があります。
このような格差をなくし、すべての人が同じ情報を得られるサービスの基盤技術を作る。それが私の研究テーマであり、その一つとして「用語の抽出」に着目しました。
 学部生時代に自然言語処理ツールを使って文章を解析していたが、望んだ通りの結果が出ないことがあった。システムに対する不満が興味となり、自分で作ってみたいと思った
学部生時代に自然言語処理ツールを使って文章を解析していたが、望んだ通りの結果が出ないことがあった。システムに対する不満が興味となり、自分で作ってみたいと思った抽出すべき用語をユーザーが自由に定義できる固有表現認識の開発
固有表現認識は、人名や地名などの固有名詞、および日付や時間などの数値表現を認識し、抽出するタスクです。しかし通常、一つのモデルは教師データで扱う用語の種類にしか対応できません。たとえば地名を扱う教師データから作成された「地名抽出モデル」は、入力されたテキストデータから地名を抽出できますが、教師データに含まれていない政府機関名は抽出できません。モデルが学習した用語クラス以外の用語抽出はできないため、データセットを作ったユーザーと目的が少し異なるだけで、他のユーザーにとって使いにくいモデルになる問題が起きるのです。
本研究で目指しているのは、巨大言語モデルが持つ用語の知識を活用し、1つのモデルでさまざまな用語抽出が可能なモデルの構築です。
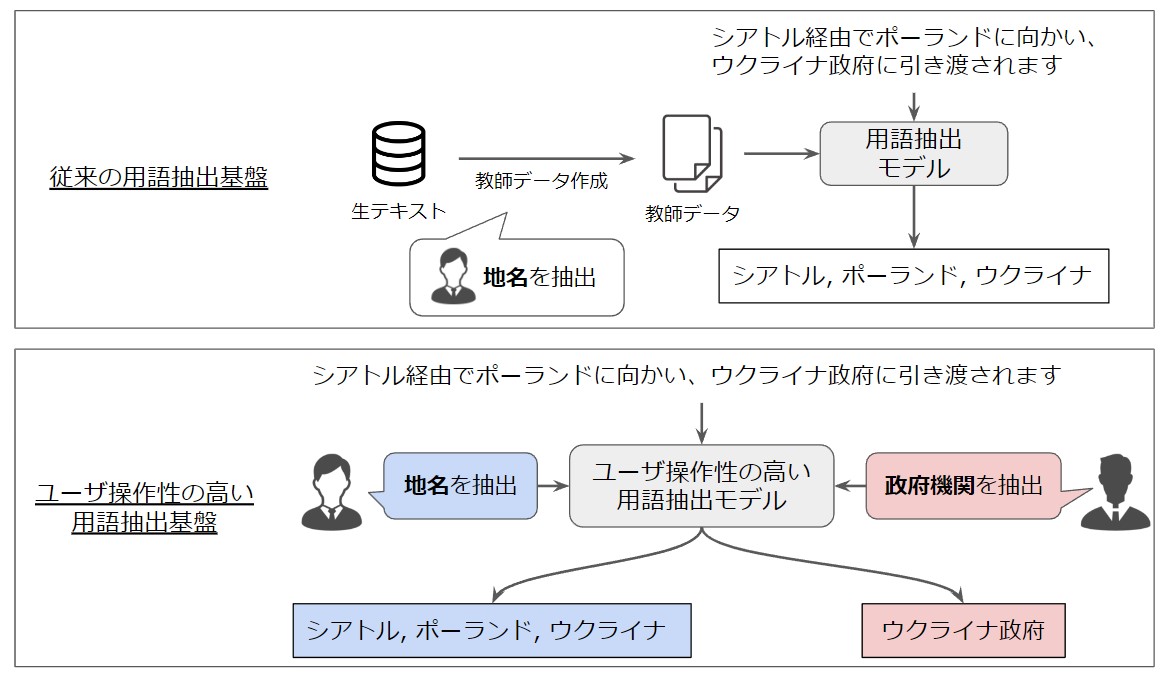 地名、政府機関、人名、施設名、日付、時間など、ユーザーによって異なる「欲しい情報」に自在に対応し、適切に抽出するモデル
地名、政府機関、人名、施設名、日付、時間など、ユーザーによって異なる「欲しい情報」に自在に対応し、適切に抽出するモデル通常、用語抽出モデルは、単語やスパンごとに抽出したい用語か用語以外かを分類するように最適化したパラメータで学習します。データセット上に定義されていない用語が抽出できない現象が起こるのは、このためです。
本研究では、ユーザーが命令した用語クラスの意味を理解し、「テキストデータに含まれている表現の中からリストアップする」生成技術を開発しています。また抽出する用語を命令する際、同時に抽出対象の例を追加することで精度の向上を図っています。
 本手法では、膨大な教師データを学習して構築されるモデルよりは性能が落ちるが、少ないデータでどこまで性能を伸ばせるのかも検証したい
本手法では、膨大な教師データを学習して構築されるモデルよりは性能が落ちるが、少ないデータでどこまで性能を伸ばせるのかも検証したい博士後期課程の3年間を「楽しんで」過ごしてほしい
このフェローシップの最大の魅力は、毎年申請のチャンスがあることです。
私は現在D3です。他の事業を含めて10回目の挑戦で、ようやく採択されました。
それまで9回もの不採択を経験し、研究者としてこうありたいという理想と現実のギャップに悩み、最も大切な「自分が何をやりたいのか」を見失っていました。信条や理想像を一度捨てて、自分自身の「やりたいこと」を見つめ直し、それを最も大切にしようと決めたとき、かつて先生からいただいた「博士課程を楽しみましょう」という言葉の意味が初めて理解できました。
このような気づきのタイミングは人それぞれだと思いますが、博士後期課程の3年間は、悩み、苦しむばかりの時間ではありません。上手くいかないときも諦めず、挑戦を楽しんでください。応援しています。
 研究の必要性を伝えるには、研究内容を事細かに語るのではなく、解決すべき課題やその前提にある問題に焦点を当てて説明することが大事
研究の必要性を伝えるには、研究内容を事細かに語るのではなく、解決すべき課題やその前提にある問題に焦点を当てて説明することが大事(取材・撮影:ライティング株式会社 酒井若菜)