
-
知能コミュニケーション研究室
土肥 康輔 WEBサイト
Kosuke Doi
外国語スピーキング能力の自動評価
自然言語処理 話し言葉 自動評価 文法誤り検出・訂正 -
スピーキングテストを簡単に受けられるシステムを
私は、元は外国語教育が専門でした。学習塾や教育系の出版社に勤めていたとき、スピーキングテストは実施や採点に人的・時間的コストがかかるため、簡単にできないことに問題を感じていました。そして、言語処理技術を応用し、人間の面接官が行うようなスピーキングテストをコンピュータで実現できれば、外国語の学習や指導を支援できるのではないか、と考えたのです。
しかし、発話中の文法や内容を機械で評価するには、教師データが必要となります。利用可能な「話し言葉」の教師データの量は、「書き言葉」よりもさらに限られています。少ないデータ量で、どうすれば話し言葉の文法誤りを検出して訂正できるのか。自由発話の内容を評価するシステムは実現可能なのか。それがこの研究のスタート地点でした。
 教育現場で感じた課題を切り口に、外国語力の向上に寄与できるものを作りたいと思い、情報科学分野の知識や技術の習得に努めた
教育現場で感じた課題を切り口に、外国語力の向上に寄与できるものを作りたいと思い、情報科学分野の知識や技術の習得に努めた高い精度で文法誤りを検出し、自由発話の内容も自動的に評価する
現在、話し言葉の文法誤り検出と訂正に向けて取り組んでいるのが、擬似誤り生成と言語モデルの活用です。
先行研究によって、擬似的に生成した誤りデータを追加データとすることで、文法誤り検出精度が上がることが明らかになっています。本研究でも疑似誤りの生成手法を工夫することで、精度の向上を図っています。さらに、言語モデルによって算出される各語の確率を利用することで、教師データを少量しか必要としない手法を検討しています。
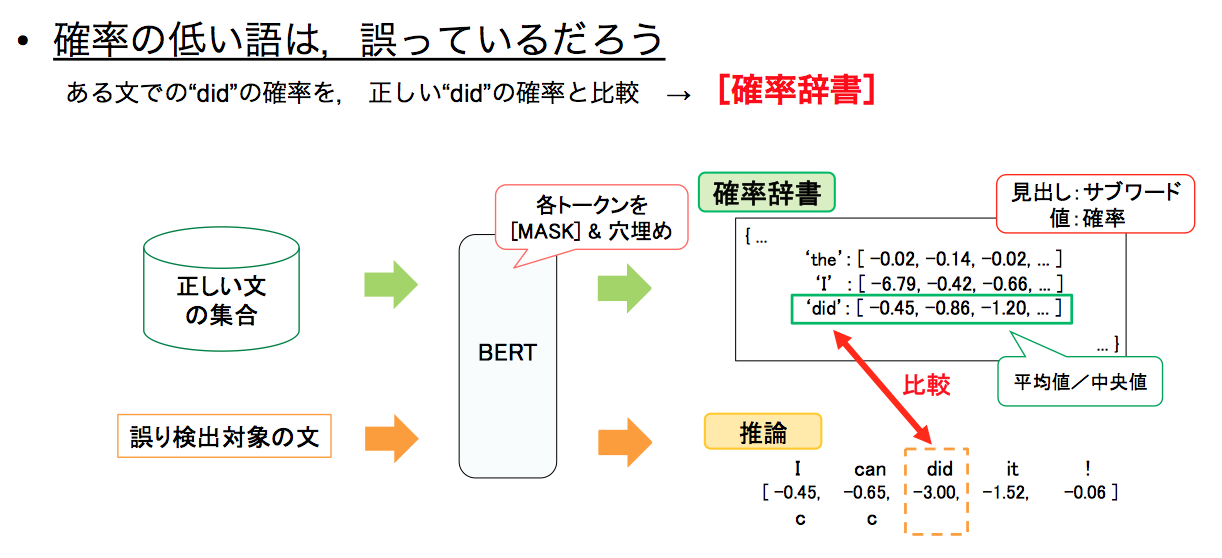 言語モデルを利用した文法誤り検出の概要。言い直しやフィラーなど、話し言葉だからこそ生じる問題をどのように処理するのかも、大きな課題のひとつ
言語モデルを利用した文法誤り検出の概要。言い直しやフィラーなど、話し言葉だからこそ生じる問題をどのように処理するのかも、大きな課題のひとつ発音や文法などの要素と同様に「発話内容」の採点も自動化する必要があると考えています。ですが、たとえば「好きなスポーツについて話してください」という問題に対する回答は、十人十色です。内容自体に加えて、発話に用いられる言語表現もさまざまであるため、質問に対して適切な内容かどうかを判断することは、難しい問題です。
回答の内容に一定の制限を設けたり、一方的に話した録音データを評価するという方法もありますが、私が理想とするのは教育現場のスピーキングテストと同じように、面接官が受験者に問いかけを行っていく方法です。自由発話の自動内容評価が実現すれば、機械が学習者の発話内容を把握し、適切な問いかけを行うことが可能になると考えています。
 個人学習で気軽に使ったり、学校など教育現場で活用できるものにしたい。「スピーキングテストを受けたくてもなかなか受けられない
という状況を変えることで、英語力の向上が実現するはず
個人学習で気軽に使ったり、学校など教育現場で活用できるものにしたい。「スピーキングテストを受けたくてもなかなか受けられない
という状況を変えることで、英語力の向上が実現するはず間口の広いフェローシップ制度、ぜひ挑戦を
民間の支援制度の中には、年齢等の制限があるものもありますが、このフェローシップはとても間口が広く、他分野の出身であっても採択していただけました。研究内容を認めていただいたことで自信がつき、より研究に専念できる環境が整いました。とても感謝しています。
今後の進路はまだ決めていませんが、大学等の研究機関に所属する場合でも、企業との共同開発に挑戦するなど、さまざまな方法で学習者や教師の役に立つものを作りたいと思っています。
 外国語教育の現場にいるのは、ほとんどが文系の人間。情報技術による解決方法はイメージしにくいため、自分が間に立ち、二つの分野の橋渡しをしたい
外国語教育の現場にいるのは、ほとんどが文系の人間。情報技術による解決方法はイメージしにくいため、自分が間に立ち、二つの分野の橋渡しをしたい(取材・撮影:ライティング株式会社 酒井若菜)