コンピューティング・アーキテクチャ研究室

ハード・ソフトの両方がわかれば微細化限界を超えられる
教員
-

教授:中島 康彦
-

客員教授:木村 睦
-

客員教授:張 任遠
-

助教:KAN Yirong
-

助教:PHAM Hoai Luan
-

助教:LE Vu Trung Duong
| nakashim@is.naist.jp rzhang@is.naist.jp kan.yirong@is.naist.jp pham.luan@is.naist.jp le.duong@naist.ac.jp |
|
| 研究室のサイト | https://sites.google.com/view/comp-arch-grp |
| 認定スタートアップ | https://lenzo.co.jp |
研究を始めるのに必要な知識・能力
世の中に存在する様々なコンピュータシステムの構成に関する好奇心。
計算基盤がブラックボックスで良いとは考えない探究心。
アルゴリズムを考えプログラムに表現できる実装力。
研究室の指導方針
まず、研究対象とするアプリケーションを選択し、次に、挑戦したい計算基盤をおおまかに選択します。その後は、文献調査に進み、既存プログラム、既存シミュレータ、様々な性能評価ツール、あるいは、デジタル回路設計ツール、アナログ回路設計ツール等を駆使して問題点を明らかにし、教員の助言を受けながら課題を設定し、解決していきます。自ら開発したプログラム、アーキテクチャ・シミュレータ、あるいは回路を定量的に評価し、対外発表を行って、最終的に論文にまとめます。
この研究で身につく能力
すでに、多くの種類の非ノイマン型コンピュータが発表されています。これらを使いこなすには、従来型コンピュータ向けの汎用プログラミング言語の知識だけでは全く不十分で、計算基盤はブラックボックスで良いと考える研究者・技術者は、徐々に取り残されていきます。入手可能なハードウェアシステムと動かしたいアプリケーションを直結させる能力、機能が不足する場合にハードウェアシステムに対して具体的な提案ができる能力、さらには、ハードウェアに合わせて柔軟にアルゴリズムを調整できる能力が身につきます。
修了生の活躍の場
以前はコンピュータメーカーに多く就職していましたが、今では、アプリケーション層に近い企業にも就職が広がってきています。ハードウェアとソフトウェアの両方がわかる人材は、これまでも売り手市場でしたが、今後、この傾向がさらに顕著になっていくと予想しています。
研究内容
半導体の性能向上が行き詰った今、新しいアルゴリズムやソフトウェアを実装できるコンピュータシステムは2択です。何年たっても同じ性能の従来型コンピュータに安住するか、アルゴリズムを直接写像する非ノイマン型コンピュータに踏み出すか、選択肢はここにあります。コンピューティング・アーキテクチャ研究室では、主に小型高性能計算基盤に焦点を当て、5つの研究グループが活動しています。
高性能デジタルアーキテクチャグループ

図1:各種非ノイマン型計算基盤
Googleなどアプリケーション層の企業が自前のアクセラレータを開発する時代が到来しています。しかし、ノイマン型コンピュータと全く異なるシステムは当初は使い難いため普及に時間がかかります。そこで非ノイマン型の中でも比較的移行しやすいシストリックリング型アクセラレータ(IMAX)の研究を進めています。GPGPUを凌駕し、LSIを単純に接続するだけでスケーラブルに性能向上できるエッジコンピューティング基盤を開発し、様々なアプリケーションプログラムを走行させています。
CMOSアナログ・アプロキシメイトアクセラレータグループ

図2:アナログ型ニューロモーフィックとストカスティック計算基盤
従来のアナログコンピュータはオペアンプによる固定関数機能のみ利用可能でした。本グループでは、任意の多入力関数を実現可能な確率的コンピューティング機構の実現を目指しています。スパイクベース計算により、デジタル回路よりも格段に高速かつ小型の回路構成とすることができます。
ニューロモーフィック・コンピューティンググループ
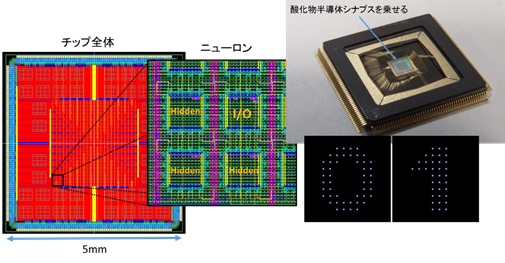
図3:ニューロモーフィックチップ
神経細胞の構造を模倣したニューロモーフィックLSIの開発が盛んになっています。本グループでは、ホップフィールドネットワーク+クロスポイントシナプス構造、および、セルラニューラルネットワーク+積層シナプス構造の2種類のLSIを研究開発しています。既に文字認識可能なレベルに達しています。最終的には、3D積層による超大規模化と脳型システムの構築が目標です。
図4:ブロックチェインアクセラレータ
超小型低電力ブロックチェインアクセラレータグループ
メモリ分散型シストリックアレイをベースとして、IoT向けブロックチェインアクセラレータについて研究しています。最適なパラメータ、新しい演算アルゴリズム、回路アーキテクチャを探索し、超小型コンピュータと組み合わせて低電力高信頼IoTデバイスの実現に貢献します。
AIアクセラレーショングループ
ベイズ推定法など、畳み込み演算主体のニューラルネットワークとは異なる機械学習アルゴリズムと高速実装技術を研究しています。GPGPU、FPGA高位合成、その他独自開発アクセラレータを計算基盤として用いています。
研究設備
富士通製スパコン富岳エントリモデル、NVIDIA製V100*4、RTX3090*4、GTX1080Ti*10、XEONサーバや、XEON/PHIサーバ、シミュレーション用サーバ、XILINX製ALVEO U280、大規模FPGA群、ZYNQボード群、試作LSI試験装置など、多数の実験設備があります。回路評価には、VDECを利用した豊富なCADツール、先端プロセスのテクノロジライブラリが揃っています。現在、シストリックリングアクセラレータ、アナログアクセラレータ、ニューロモーフィックLSI,ブロックチェインアクセラレータなどを開発しています。各自の机にはマルチモニタの高性能Linux-PCを設置しています。
研究業績・共同研究・社会活動・外部資金など
- 研究業績:2006年研究室創設以降、研究室メンバの受賞25件、査読付論文・国際会議164件、特許21件、招待講演含む口頭発表173件
- 共同研究:海外企業・大学、国内企業・大学等
- 社会活動:国際会議・国内学会・研究会・各種委員会の委員長、幹事団、運営委員等
- 外部資金:2006年研究室創設以降、科研費基盤(A) 3件、基盤(B) 1件、若手 3件、挑萌芽 3件、NEDO 2件、JST(ALCA-Next 1件、ALCA 1件、さきがけ 4件、A-STEP等 3件)、STARC 3件、企業10件以上