Generally, the environment is non-stationary and complex, and hard to approximate for a single controller. One solution is to use multiple forward and reward models of the environment. Each forward and reward model makes a local approximation of the dynamics and reward function.
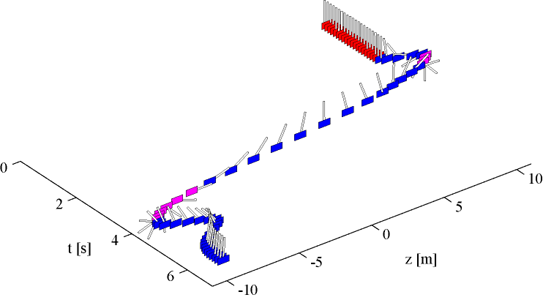
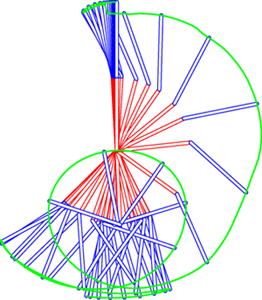
For the proposed algorithm (?), we tested the performance for a non-linear, non-stationary cart-pole task. For t=0-2 s the peak of the reward function was z=10 m, then the peak moves to z=-10m. Fig. 1 shows the trajectory of the cart-pole. The color of the cart represents a particular (?) reward model. Next, we try for the acrobot swingup task, which has a strong non-linearity. Fig. 2. shows the results. Despite the strong non-inearity, the agent could succesfully learn to swing up.
|
|
|