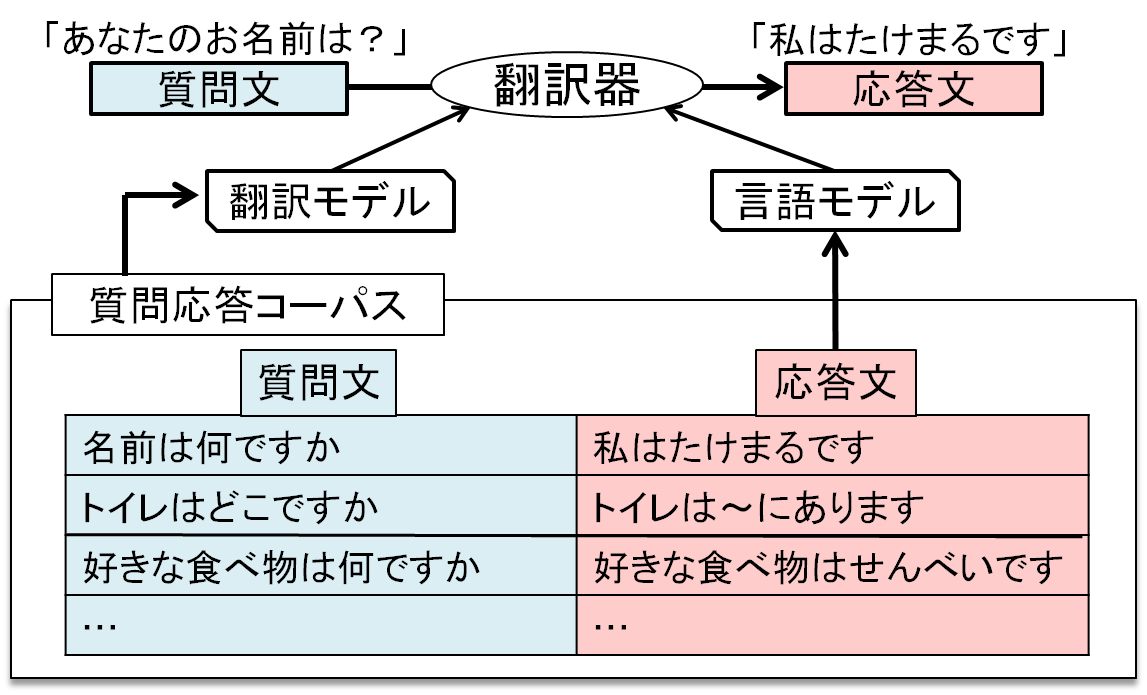
ユーザとのインタラクションを改善するための方法として応答文に多様性を持たせることが考えられる. 本研究では応答文に多様性をもたせるための手法として統計的機械翻訳による応答文生成を提案する. 提案手法は質問文と応答文を別の言語とみなした翻訳を行うことで質問文を応答文に変換しようとするものである. 書き起こし文による実験を行ったところ,適切な応答の生成率が約60%あり,新たな文表現の応答文も生成され,手法の実現可能性が示された. 更に音声認識仮説を複数用いて学習と入力を行ったところ,適切な応答の生成率が約10%向上し, 実用のシステムに搭載するにはさらなる性能改善が望まれるが,本手法による柔軟な応答文生成の可能性が示唆された.
キーワード:音声対話, 応答文生成, 統計的機械翻訳, 音声認識仮説, 実環境データ